
“Machine Learning” is not just a buzzword — arguably, it is two. Almost everybody seems to be using Machine Learning (ML) in a way or another, and those who aren’t are looking forward to use it. Sounds like a good topic to know about. I did some nice Neural Network stuff with some colleagues in school in the late 90s1. Maybe I could just brag that I have nearly 20 years of experience in the field, but this would not be exactly an honest statement, as I didn’t do much ML since then.
Anyway, this is a fun, useful and increasingly important field, so, I guess it is time to do some ML for real. Here’s the first set of notes about my studies, in which I present some important concepts without getting into specific algorithms.
Coursera’s Machine Learning Course
I started my endeavor with the Machine Learning course at Coursera, taught by Stanford’s Dr. Andrew Ng (of Google Brain fame2). The course is very well-thought-out, the programming assignments illustrate several important points and Professor Ng gives quite a few good insights in the lecture videos. I honestly expected it to be a little better polished (for example, there are some portions of the videos which were clearly meant to be edited out), but don’t let this fool you: the course is great and I highly recommend it!
In this post I intend to discuss Machine Learning from my own perspective, which is formed from different sources, but Coursera’s course is surely one the biggest influences on what I am writing here.
What is Machine Learning?
I think there are two important ways to answer to this question. The first one is based on what I see as the biggest motivation for Machine Learning: some of the problems we want to solve today are immensely difficult. Much, much more difficult than the problems we have been solving in the last decades. We are reaching the limits of what we can do with the traditional programming approaches, in which we have to understand and manually program every minimal detail of the solution.
Arthur Samuel, the man who coined the term in the late 1950s3, defined Machine Learning on these grounds:
[Machine Learning is] the field of study that gives computers the ability to learn without being explicitly programmed.
— Arthur Samuel
The second way to answer to that question is more technology-oriented. Is “genuine Machine Learning” somehow limited to certain tools or algorithms? Can we say that something is not ML just because it is implemented using this (instead of that) algorithm? I think the answer to these questions should be “no”, and it looks I am not alone here. Tom Mitchell, a prominent researcher in the area, said:
[W]e say that a machine learns with respect to a particular task T, performance metric P, and type of experience E, if the system reliably improves its performance P at task T, following experience E.
— Tom Mitchell
So, any system that we can fit in this simple structure can be called Machine Learning. A statistician could look at a certain system and say “Hey, but this just a linear regression!” Well, yes, it might be just a linear regression, but it is still ML: all the required ingredients are there.
Categorizing Machine Learning
There are different ways to categorize ML algorithms and applications, and I guess none of them is perfect. I’ll focus on one of the common categorizations, and will give but a few examples. You can find more examples easily around the Internet.
The two main categories of ML are supervised learning and unsupervised learning. In both cases, the algorithms learn from a set of data samples called the training set (though, as we’ll see, these samples are different in each case).
Supervised Learning
In supervised learning, the training set is comprised of what is called labeled data. Each training example contains not only the inputs, but also the expected (correct) output. The algorithm learns from these examples and, hopefully, it will learn to generalize, so that it gives us correct answers even when given inputs it has never seen before. Mom tells the kid to never take candy from a stranger, but she hopes that the kid will also refuse salty snacks from that random weirdo.
Supervised learning algorithms are often used in prediction tasks: we want to determine some value based on a set of inputs. If we want to predict a continuous value, we say that we have a regression problem. If we want to predict a discrete value, we have a classification problem.
Suppose you have an orange farm. For years, you have scanned leaves of your orange trees along with notes of how many oranges the tree in question produced every year. Now you want to use this dataset for a supervised learning algorithm. After training, you’ll input a scanned leaf to your ML system and it will give you a prediction of how many oranges that tree will produce. This would be a case of regression, as the number of oranges is a continuous value.4

In regression, features (the funny colored shapes) are mapped to numeric values. From the training set (on the left) the system learns how to generalize and estimate the value for inputs never seen before (on the right).
Now, suppose that, instead of recording the productivity associated with each leaf, you recorded if the tree was healthy or if it had some disease. You can still use this data for a supervised learning algorithm. But now it is a case of classification, as your output will be limited to a discrete set of possible values (like “healthy/not not healthy” or, perhaps, “healthy/disease A/disease B”).
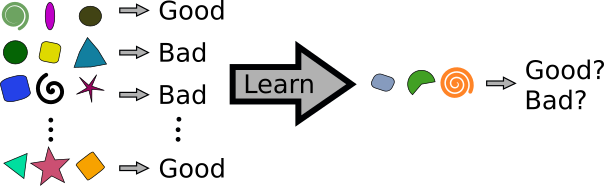
In classification, features are mapped to discrete classes (here, either “good” or “bad”). From the training set the system learns how to generalize and predicts the class corresponding to inputs never seen before.
And no, I don’t own an orange farm. I don’t own even a single orange tree and I have no idea if this example makes any sense in the real world of orange farming. Anyway, two more down-to-earth applications of supervised learning are estimation of real-estate prices (regression) and spam filters (classification).
Unsupervised Learning
The other main category of algorithms, unsupervised learning, is a bit different: our training set is made of unlabeled data. We don’t know beforehand what is the expected output for a given input. It’s just data, and we don’t know that much about it. Instead of trying to predict something, we are now trying to find some structure in this mess.
Unsupervised learning is used mainly in clustering applications. A clustering algorithm will take our data and group them in, well, clusters. With some luck, these clusters will provide us some insight about our data.
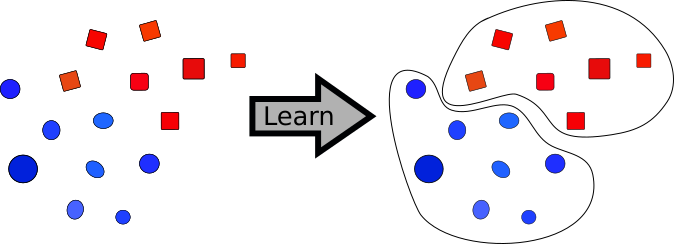
In clustering, the training set is divided into groups (or clusters) according to their similarity.
Now your orange farm has prospered. Unfortunately, some of your trees are producing much less than the average. What if, you wonder, these low production trees have some genetic mutation? And what if, you wonder further, there actually various different genetic issues behind this? You know, maybe the same symptom (low production) can be caused by different “bad genes” in different trees.
So you take DNA samples of all your problematic trees (the farm is prospering, you can afford this!) and feed them to a clustering algorithm. The algorithm will group these DNA samples according to some kind of similarity it detected among them. Perhaps each of these groups represent a different genetic problem leading to low production.
Again, I have no clue whether this example is realistic or not (though I have seen it mentioned once or twice that clustering can be used in DNA analysis). A real-world example of clustering would be market segmentation: how to group your customer base such that you can design a new line of products that fits their tastes well?
Unsupervised learning is also used in some non-clustering applications, and outlier detection (AKA anomaly detection) is a prominent example. Our training set contains lots of examples of whatever we consider normal.5 The algorithm learns that, and then is able to detect when some abnormal input is given to it. This is used quite a lot in fraud detection (in credit card transactions, for example), but also has uses in quality control (“is this thing we just produced good enough to be sold?”) and monitoring (“is any of our machines about to explode?”).
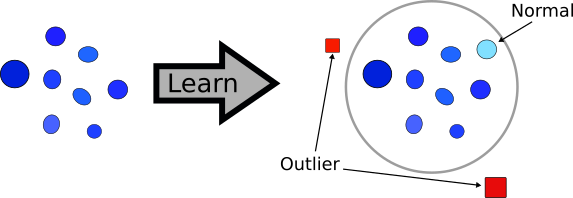
In outlier detection, the system learns from the training set what is considered normal. Then, given unseen examples, it can classify them either as “normal” or “abnormal” (outlier).
Other Categories of Machine Learning
For completeness, I must mention a third category: reinforcement learning. In this type of learning, the system learns as it performs the task, based on some kind of feedback. Say you want to make a ML system learn how to drive a car. If the system drives nicely for a few seconds, you give it some fish. If it crashes the car, you whip it. It may destroy quite a few cars, but it will eventually learn.
I have seen reinforcement learning being used in some cool things (like learning to play video games), but as far a I know, they are not used that much in practical applications.
Recommendation systems (AKA recommender systems) are also important ML applications, seen in virtually any online shop and service. “If you liked this, you may also like that.” I don’t know about the experts, but I cannot easily fit them in any of the categories above. In a sense, they are based on labeled data (the ratings you have given to products), but for me it looks they work so differently than our regular regression or classification algorithms.
I mentioned earlier that other categorizations are possible. I’d like to mention one of the alternatives: ML can be either offline (AKA batch) or online. With offline learning, the system is trained before it is put into production. Once it is in production, it doesn’t learn anything else. Got more training data and want to use it to improve the system? OK, retrain it from scratch, retest, and redeploy.
With online learning, the system learns (or maybe keeps learning) as it is used by real users. This can be nice for whoever has a good, continuous flow of users (think of major web sites). Imagine a recommendation system based on online learning: it can adapt itself if the demographics of the web site users change.
What’s next?
This has become a long and boring post and I said just half of what I intended to say. Therefore, I’m splitting my original post in two long and boring posts. The next one will get a bit more on how Machine Learning actually works. I’ll still not talk about any specific algorithm, I just want to show what I see as the common theme among several of them.
-
Before it was cool.TM ↩︎
-
In 2012 a team of researchers (which included Prof. Ng) published a paper with some groundbreaking ML work; the press reacted by flooding us with headlines like “Computers Learned to Identify Cats by Watching YouTube videos”. ↩︎
-
And you thought this was high-tech, uh? Samuel worked in what-we-now-call-machine-learning since 1949! ↩︎
-
The number of oranges is an integer value, so it is technically discrete. The point, I guess, is that this value kind of behaves as if it were continuous: there is a large number of possible values and they are all neatly ordered and increasing in the same pace. If the system predicts that a tree will produce 86.23 oranges we know this can’t be strictly true, but the value conveys some very understandable information, doesn’t it? In terms of modeling, it just makes much more sense to treat this value as continuous. ↩︎
-
This is just me wondering: if we assume that the examples in the training set are representatives of whatever is normal, aren’t we implicitly labeling the data? Is it really correct to call outlier detection unsupervised learning? Is there some deeper truth behind the supervised versus unsupervised learning categorization? ↩︎